
INTRODUCTION
Reverberation has a severe impact on the intelligibility of a speech signal and, despite all recent advances in acoustic modeling, still deteriorates the performance of automatic speech recognition (ASR) systems significantly, even when trained on large scale data [1], [2]. In these challenging far-field scenarios, signal processing to dereverberate and thus enhance the signal can help to mitigate the performance losses. Many techniques have been proposed for signal dereverberation, which can be broadly categorized in linear filter ing approaches and spectral subtraction like approaches for magnitude or power spectrum manipulation [3].
Weighted prediction error (WPE) dereverberates the signal by estimating an inverse filter which is used to subtract the reverberation tail from the observation and thus falls into the first category. It can operate either on a single channel or in a multiple-input multiple-output fashion on multi-channel data. The quality of the estimated filter coefficients mainly depends on the estimation of the PSD of the "anechoic speech", i.e., the direct speech signal and its early reflections. Since this signal is unknown, the vanilla WPE works iteratively by alternating between two steps: (Step 1) Dereverberating the signal using the current estimate of the anechoic speech PSD, and, (Step 2) estimating the anechoic speech PSD using the current estimate of the dereverberated signal. Alternating these two steps gradually improves the estimate of both, the (dereverberated) target signal and the anechoic speech PSD. This, however, inherently makes the vanilla WPE an offline method and computationally expensive.
To overcome this dependency issue – and enable an on-line usage of WPE – we recently proposed to utilize a neural network to directly estimate the PSD from the observation [4] [5]. We could show that this leads to improved performance for low-latency solutions compared to a more simple PSD estimation [6]. However, we now need parallel reverberated and non-reverberated data in order to train the PSD estimation network, limiting the applicability of the approach.
In this work, we lift this restriction by combining the WPE front-end with the acoustic model already during training. This allows us to train the estimator directly with a suitable ASR loss. Apart from an expected performance improvement like we saw with e.g. beamforming [7], the motivation for this is threefold:
Calculating a training target for the PSD estimator requires a corpus of parallel data. Building such a corpus is almost only possible by simulating the observed data, inevitably leading to a mismatch between training and test data.
There is no clear notion which part of the signal should be considered as anechoic or the target signal respectively. Thus, the training target for the PSD estimator is not well-defined. Where as the network can adjust to the acoustic model needs when trained jointly.
If other directed noise sources are present, their contribution to the covariance statistics could be optimized by an appropriate weighting factor for the tf-bins in question.
We investigate the performance of such a joint system and compare it with one separately trained on oracle PSD information.
SCENARIO AND SIGNAL MODEL
Using D microphones, we observe a signal which is represented as the D-dimensional vector yt,f at time frame index t and frequency bin index f
in the short time Fourier transformation (STFT) domain. In a far-field
scenario, this signal is impaired by (convolutive) reverberation. We
assume, that for ASR the early part of the room impulse response (RIR)
is beneficial whereas the reverberation tail deteriorates the
recognition and should therefore be suppressed. Specifically, we
consider the first 50 ms after the main peak of the RIR (h(early)) to contribute to the anechoic signal whereas the remaining part (h(tail)) is assumed to cause the distortions. In the STFT domain we denote this model as follows:
![]()
WEIGHTED PREDICTION ERROR
WPE
estimates the reverberation tail of the signal from previous samples
and subtracts it from the observation to obtain an optimal estimate of
the anechoic speech in a maximum likelihood sense:
![]()
Using ∆ ≥ 1 avoids whitening of the speech source. WPE maximizes the likelihood of the model under the assumption that the anechoic signal is a realization of a zero-mean circularly-symmetric complex Gaussian with an unknown time-varying variance λt,f.
3.1. Iterative WPE
There is no closed form solution for the likelihood optimization, but an iterative procedure which alternates between estimating the filter coefficients gfd and the time-varying variance λtf exists:
Step 1)
![]()
Step 2)
![]()
The heuristic context of (δ + 1 + δ) frames helps to improve the variance estimate in this iterative scheme [8].
3.2. Recursive WPE
To derive a recursive formulation, the correlation matrix is estimated with a decaying window:
![]()
This leads to a recursive solution with the following rank-one updates [9]:
![]()
Here, Gt,f are the stacked filter taps gf,d for each microphone. Note that these are now time variant. This is in essence a Recursive Least Squares (RLS) adaptive filter for the reverberation estimation. The authors of [6]
approximate the PSD of the target signal using a smoothed PSD of the
observation averaged over the microphones using a left and right context
δL and δR:
![]()
PROPOSED FRAMEWORK
4.1. PSD estimation
Given the statistics λt,f of the underlying anechoic signal, the optimal filter coefficients for WPE can be calculated in closed form with Eq. 5 or adaptively with Eq. 10. But since we can only observe the reverberant signal, these statistics have to be estimated. Consistently with [4] and [5], we focus on a deep neural network (DNN) for PSD estimation.
In particular, we use the same network architecture as in the works above. The network consists of a long short-term memory (LSTM) layer with 512 units, two linear layers with 2048 units and ReLU activation functions and a final linear layer with 513 units. It operates on a single channel and the final estimate is obtained by averaging over all channels making it independent of the number of channels and the microphone configuration.
As a baseline, we consider estimating λt,f by a comparably simple smoothing of the spectrum as specified by Eq. 11 which has also shown good performance in [6] and [5] (with δL = 1 and δR = 0).
4.2. Acoustic model
Our acoustic model is a wide bi-directional residual network (WBRN) as proposed in [5]. It consists of several convolutional layers with residual connections, followed by two BLSTM layers and two linear layers. The hyper-parameters as well as the initial training procedure were adapted from [10]. The model is trained on frame-wise senone targets and shows very competitive performance on the task at hand. Note that the acoustic model itself operates offline since we focus on the effects of the front-end but can be replaced by an online version to achieve a fully online operating system.
4.3. Training
The acoustic model is first trained using multi-condition data of the respective corpus until convergence. For the DNN based PSD estimator, we train different variants.
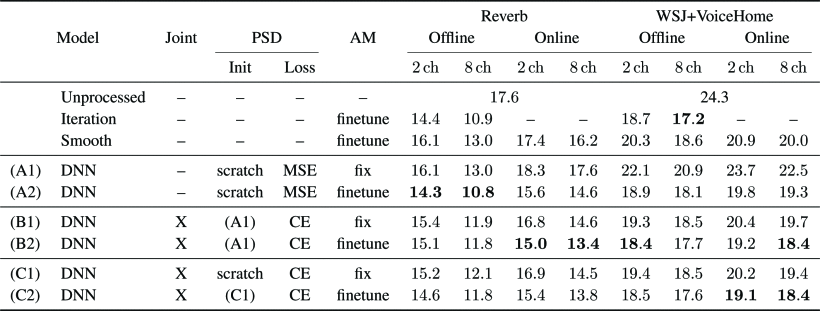
The first one (A1) is our baseline and we train the PSD estimator separately as described in [5] and [4]. The anechoic speech PSD is used as the target for a mean-squared-error (MSE) training.
For the second one (B1), we utilize the acoustic model loss to finetune the estimator trained separately. This model still needs the parallel data (for the initialization) but might result in improved overall system performance as we directly optimize for the ASR target.
Third (C1), we train a PSD estimator with random initialization using the state level cross-entropy (CE) loss but keep all the parameters of the acoustic model fixed, i.e. use it as a loss function w.r.t. the PSD estimator.
Note that we backpropagate either through the offline equations (Eq. 3–Eq. 5) or the recursive formulation (Eq. 8–Eq. 10) respectively. Because the backpropagation through the online variant needs a lot of memory, this calculation always runs on the CPU where we can utilize the system memory. Since it is also computationally very expensive, we do not train it directly form scratch but rather first train the offline system from scratch and then switch to the online variant after an initial training phase.
Finally, we finetune the acoustic model for all variants with a learning rate of 10−5 using the respective WPE front-end. These systems are referred to as (A2) – (C2), each of which corresponds to the variant (A1) – (C1). If applicable, we jointly optimize both models in this step. Otherwise, just the acoustic model is finetuned. To increase the diversity of the training data, we sample the delay ∆ to be in a range between 1 and 4 and the number of taps K to be between 5 and 10 during this step.
EVALUATION
To demonstrate the versatility of the described approach, we evaluate the proposed systems in terms of WERs on the data of the REVERB challenge as well as on WSJ+VoiceHome data.
The REVERB challenge dataset [12] contains simulated and real utterances. For simulated data WSJCAM0 utterances [13] are convolved with measured RIRs. Noise is added with ∼20 dB signal to noise ratio (SNR). Reverberation times (T60) are in the range of 0.25 – 0.7 s. The real data consists of utterances from the MC-WSJ-AV corpus [14] which are recorded in a noisy reverberant room with a reverberation time of ∼0.7 s. The corpus is known for its mismatch between the simulated data used during training and the real recordings for evaluation. To reduce this discrepancy, we randomly sample the SNR to be in the range of 5 dB – 30 dB and scale the signal with 0.2 for the training of the PSD estimators and all finetuning experiments [4]. The initial acoustic model is trained on unscaled data without SNR perturbation.
For WSJ+VoiceHome we convolve WSJ utterances (5 k vocabulary) with VoiceHome RIRs and VoiceHome background noise [15] with reverberation times (T60) in the range of 395 – 585 ms. This is similar to the simulation setup proposed by Bertin et al. [16]. The VoiceHome background noise is very dynamic and typically found in households e.g. vacuum cleaner, dish washing or interviews on television and the SNR ranges from 0 dB – 10 dB.
We evaluate the performance for two and eight microphone channels. Since WPE preserves the number of channels, we always take the first one and use it for decoding with the acoustic model. For decoding, we use the 3-gram language model from the WSJ0 corpus without any rescoring afterwards.
For WPE we use a DFT window size of 512 (32 ms) and a shift of 128 (8 ms). For the recursive WPE variant, we set α = 0.9999 and for vanilla WPE the number of iteration to 3. For all variants, we vary the delay parameter in a range between 1 and 4 and the number of filter taps is set to either 5 or 10. These values are determined on the development set and can be different for each configuration.
Our baselines for evaluation are Unprocessed, Iteration and Smooth. These use the first channel without any enhancement, vanilla WPE iterations and the smoothing PSD estimator (see. Eq. 11) respectively. These are compared with the neural network variants trained as described in Subsec. 4.3.
These systems are evaluated for two different latency constraints (where applicable): offline and online. Offline means, that the whole utterance is available for processing and this is our baseline scenario. For the online setting, which is our target scenario, we use the recursive formulation of WPE (Eq. 8–Eq. 10) and the system operates on a frame-by-frame basis.
All results are shown in Tbl. 1. First note, that the unprocessed baseline itself already achieves very good performance. For comparison, the recently updated Kaldi system achieves a WER of around 19.7 %2 on the Reverb dataset. All fine-tuned systems improve upon the unprocessed baseline irrespective of the PSD estimator or the latency constraint showing the effectiveness of a WPE front-end. As another general tendency we can see that the DNN supported systems outperform the baselines, especially in the online case we were focusing on. For the offline use-case, using the vanilla WPE formulation with iterations seems to be most suitable though, especially when considering the system complexity.
For the online use-case however, using a DNN-based PSD estimator and training it with the ASR criterion is more effective. One reason for this might be that the PSD can be implicitly tuned for faster convergence of the filter estimation in this case. The best results are achieved if the PSD estimator is pre-trained using parallel data and then finetuned jointly with the acoustic model. If no parallel data is available, the PSD estimator can also be trained from scratch with little to no loss in performance. All this applies to both tested corpora and therefore for highly reverberant as well as reverberant and noisy household-like scenarios.
CONCLUSIONS
In this paper we demonstrate that jointly optimizing a DNN based PSD estimator and the acoustic model improves the performance for online dereverberation with WPE by 8 % – 18 % in highly reverberant as well as noisy reverberant scenarios compared to a baseline smoothing PSD estimator. Being able to backpropagate through the filter estimation further lifts the requirement for parallel training data and further allows to potentially train the PSD estimator on real data to reduce the mismatch between training and inference with minimal impact on the overall performance.
ACKNOWLEDGEMENTS
This work was in part supported by a Google Faculty Research Award. Computational resources were provided by the Paderborn Center for Parallel Computing.
